Algobola was an experiment investigating social contagion. Using twitter as a propagation channel, I introduced the ‘virus’ into the network, using myself as patient zero. I started the infection at 13:00GMT on 28th October 2014.
I knew from the start that there was a danger Twitter would close it down, but I didn’t expect it to happen so soon. Ironically, it appears my bot was automatically flagged and restricted by one of Twitter’s own internal bots – my bot was caught by a bot-policeman…
However, before that happened it managed to expose over 900 people to the virus, each of them being notified via a personalised notice informing them of their changing status as their infection developed.


The parameters were modelled on Ebola, but modified to take into account the limited attention span of social media users. Once infected, the subject remained infectious to others for 72 hours. At that point, they either survived or died (30% survival rate). Twitter restricted posting rights of the account after about 70 hours, just before the first subject (me) died.
However, even though I could no longer inform the victims, I could still simulate the infection and record the way it propagated through the network. Indeed I continued until Twitter completely stopped API access for the account on 4th November. By this point, 5230 users were exposed.
What emerged is a fascinating chart of social media connections.
I’ve made a visualisaton of some of the data I collected. Each dot represents a twitter user, and the connections between them indicate the vector of infection. Click ‘start’ to cycle through the first 120 hours of infection, or use the buttons to jump to a specific day. If you hover your mouse over a dot it will give you the name of the twitter user.
Click here to launch the interactive view.
Maybe you can find yourself in there.
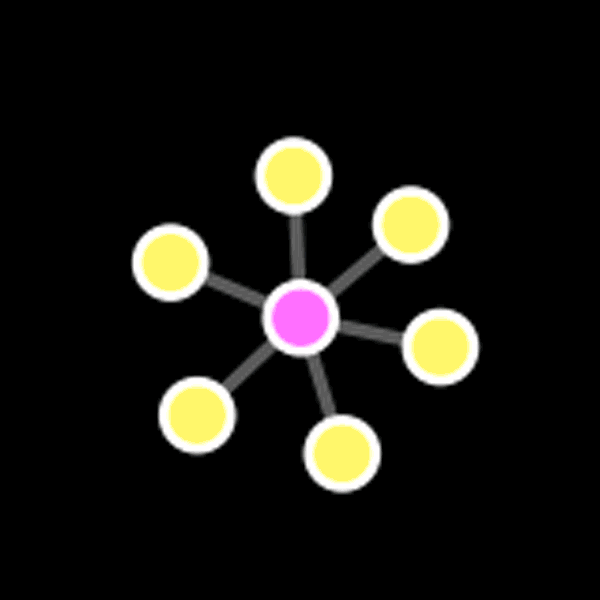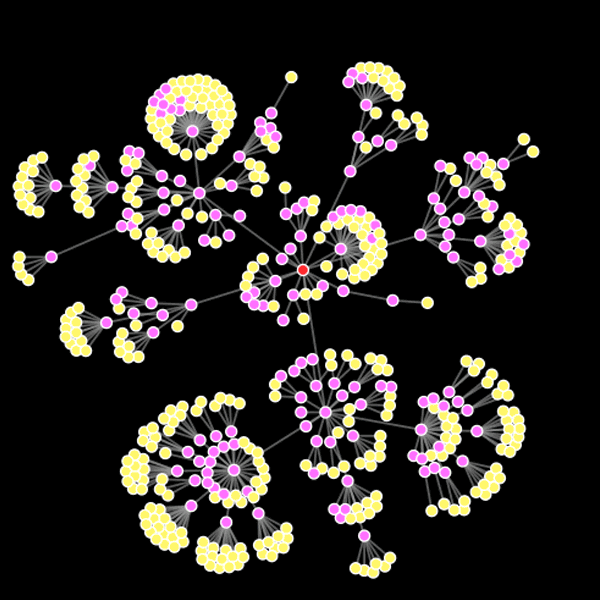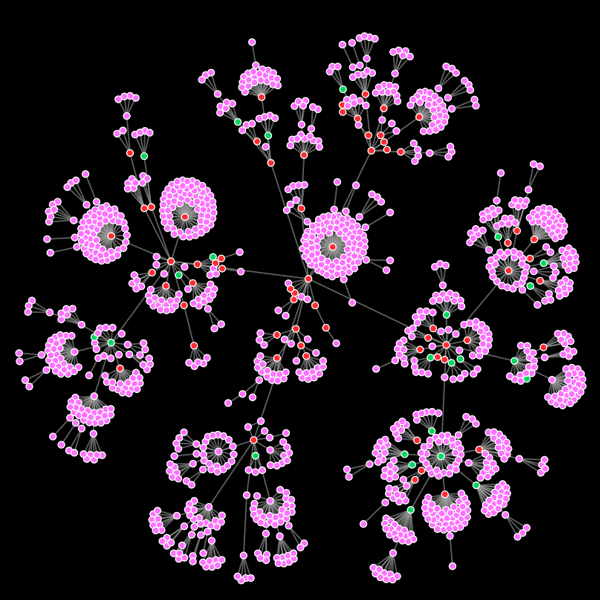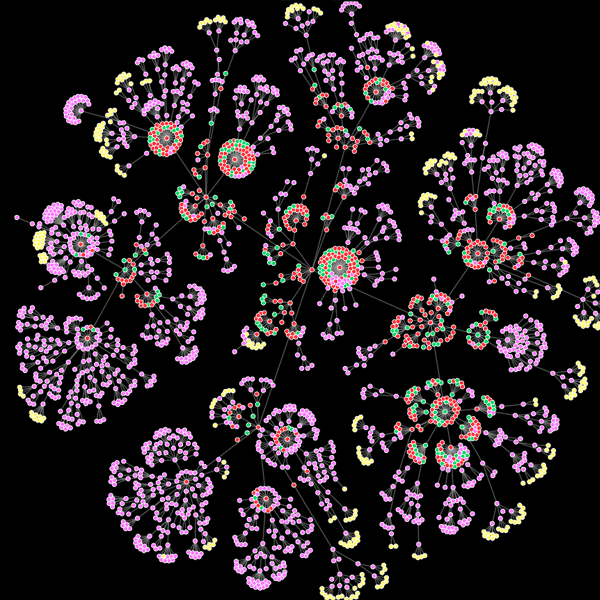
What emerges is a rapidly exploding map of social interactions. It gives a quick visual representation of the different kinds of social media users – those who communicate with a select few, and those with a larger network of contacts. It exposes the interrelatedness of the twitter users – who their friends are, how often they communicate – all derived from a very simple analysis of the ‘metadata’.
This stuff is sexy to both data scientists and governments. Which government wouldn’t want to harvest this data? As we live our lives on a connected, easily monitored infrastructure, these kinds of data become a convenient shortcut to our identity as individuals. To all intents and purposes we are our data. These kinds of data represent who we are. We are packets of data, flung into the ether, to be collated and analysed by giant server farms in hidden locations.
Once the data is collated, it is algorithmically analysed. A digital report card is produced, and based on the desires of the enquiring party, ‘persons of interest’ are identified. Sometimes these profiles are produced by marketing companies, like Facebook, hoping to sell ever more granular descriptions of us to entities that wish to advertise to us. Sometimes these profiles are produced by government agencies, hoping to identify individuals as subjects of ‘interest’.
In both cases, the raw data is the same. The data itself is benign until it is interpreted. It’s the algorithmic questions posed of it that produce the representations that humans actually use to make decisions. This recasting of information is possible because of the computational power available, it is necessary because the human mind is incapable of extracting inference from datasets of this size. An awful lot of trust is being put into this inscrutable algorithmic perception, and the track record in this area is not good.
The real issue is one of ethics – Do we want our governments to do this? Is there any evidence that it makes us ‘safer’? How does a legal system deal with humans rendered as data? Do you have the same rights over our digital selves? What is the relationship between the data-self and the real-physical self?
I shall be speaking about these ideas and more in Brighton next week.